Volt MX Foundry console User Guide: Service
Monitoring
App Services provides the monitoring capabilities on server performance to provide information on server load, performance, errors and so on to the end user. A dashboard that captures the real time monitoring data such as traffic flow (number of calls per service), performance (total duration of the calls) and error rate (count of errors per service) of the server is displayed. Monitoring data is retained for a week.
Admins can set performance thresholds for individual services and automatically send email alerts when thresholds exceed the predefined time settings.
To access the Monitoring, follow these steps:
-
Log on to App Services. For more information on accessing App Services, refer Launching App Services.
Upon successful login, the Web Apps page appears.
-
Click Monitoring from the left pane of the screen.
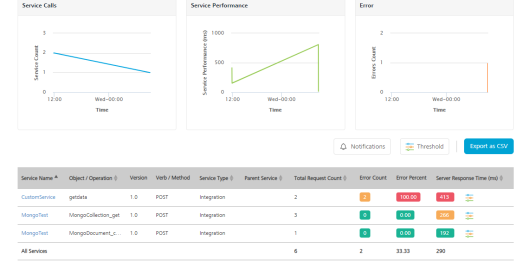
The Monitoring page appears with the list of services that hit the server.
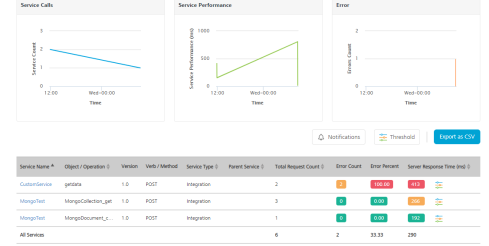
Enable Monitoring
Select the check box to enable monitoring. If Monitoring is disabled and the log level is debug, then it logs the metrics in the DB.
If Log Level type is set as Debug or lower in Client Log Level filter, the monitoring is captured only for the users matching the filter criteria in the log. If the service monitoring feature is enabled, the client log level set has no effect on it and data is collected for all the users. For more information on client log filters, refer Log Level by Client Filter.Note: Monitoring has no perceptible performance impact and it is highly recommended to keep the feature enabled.
The Monitoring page has two tabs - Service and Environment.
Service
The Service tab displays the performance data as graphs to view the overall performance and a table with the information for each specific service such as count of the server requests, duration, and other performance metrics.
The performance data of the services is displayed by default. In the search field, enter a service name/ operation and click the Search icon to view the performance data of the specific service/ operation. The following three graphs represent the real-time data monitoring:
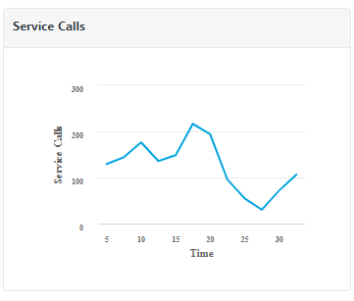
Service Calls
The graph displays the number of service calls received by the server within the selected time period.
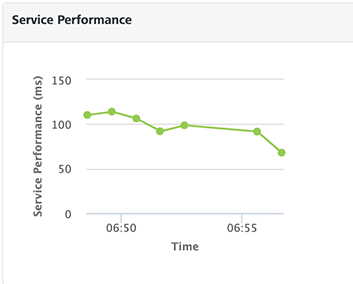
Service Performance
The graph displays the performance of the server in terms of time taken by the server to respond to the received request within the selected time period.
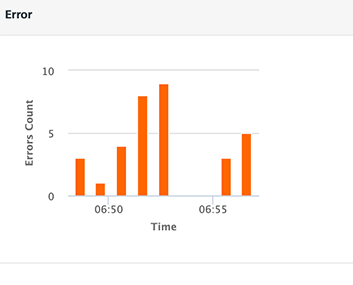
Error
The graph displays the count of occurrence of errors from the total number of requests within the selected time period.
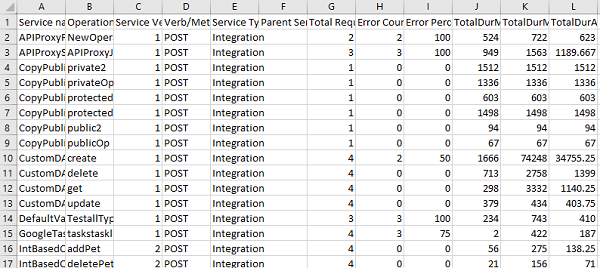
The table for Service Monitoring displays the following information:
Field Description Service Name Name of the displayed service. Click the service name to navigate to the test page of the selected service.> Note: Click on a specific row of a service (other than service name) to view the statistics of that service. To revert to the default graphs page, click anywhere else on the screen. Object/Operation The object for the Object service or the operation created for the Integration/Orchestration service. Verb/Method The verb (or) method created for the service. Service Type Type of the created service. (example: Object Service, Integration Service and so on.) Parent Service Details of the parent service that invoked the service.Example: If an Integration service is invoked as part of an Orchestration service, the orchestration service's operation name is displayed in the Parent Service. <Operation_Name>.> Note: From V9 Service Pack 1 the parent service name is also added to the parent service's operation name to uniquely identify the parent operation.Example: If an Integration service is invoked as part of an Orchestration service, the orchestration service's operation name is displayed along with the orchestration service name, in the following format:<Orchestration_ServiceName>/<Operation_Name>.> Note: From V9 Service Pack 2 the parent service name is also added to the service tasks, which are part of the workflow service to uniquely identify the parent workflow service.Example: If any service is invoked as part of a worflow service task, the workflow service's name is displayed along with the workflow service task service name. In the following screen shot, under Parent Service column, the Loan_Approval is the parent service (workflow service) name associated to the workflow service task.
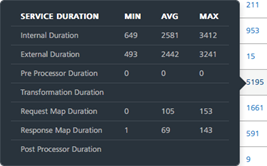
Total Request Count The count of total requests sent from the service within the selected time range. Error Count Count of the errors received from the total requests sent. Error Percent Percentage of the errors received from the total requests sent. Server Response Time Time taken to respond by the server for the received request.Mouse hover across each row to view the time split of service performance. For detailed information on time split refer Time-split for Server Response time. Time-split for Server Response time: You can view the details of the service performance in terms of the minimum, maximum and the average time spent on each of the logical components. The details include the time spent while executing the request in terms of external call to backend and in transforming the backend request to fit the requirements of the client app. It also provides the details of pre-processor and post-processor duration along with request and response mapping duration for Object services.
Note: You can sort the displayed data in the table using the Service Name, Object (or) Operation, Service Type, Parent Service, Total Request Count, and Server Response Time.
Following actions can be performed in this screen:
Export as CSV
You can export the data displayed into CSV format. To export the data, perform the following steps:
- Click Export to CSV button, to export the data into a CSV file.
Note: The exported CSV has
|(pipe)as a delimiter.
Note: From V9 Service Pack 1, two new columns to represent 90th percentile (P90) and 95th percentile (P95) are added.
Time Range Filter: You can filter the data using the time range filter. The default time range of the services displayed is 15 minutes. Select a time range to view the list of services that hit the server within the selected time range.
Note: Any existing metrics are logged in batches into the DB at the end of every minute.
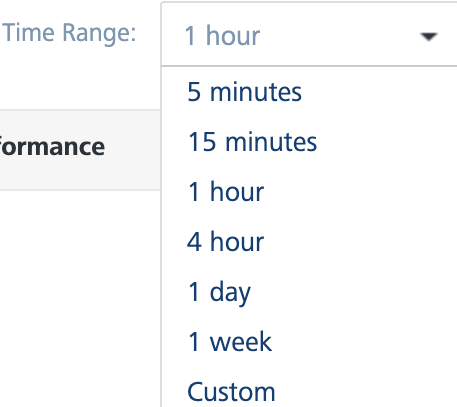
The following are the different time ranges displayed in the drop-down list:
- 5 minutes
- 15 minutes
- 1 hour
- 4 hours
- 1 day
- 1 week
Custom Time Range
Excluding the default time range displayed, you can also select the custom time range to view the list of services that hit the server within the selected time range.
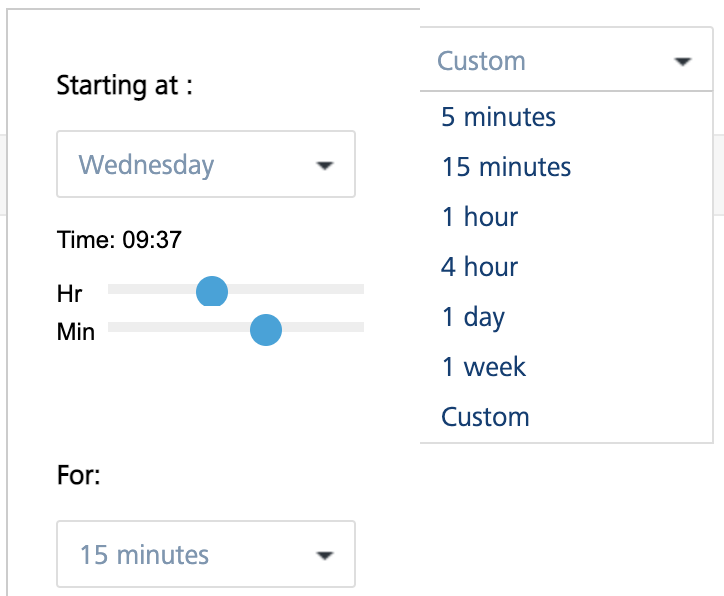
To select the custom time range, follow these steps:
-
In the Time Range drop-down list, select Custom.
A pop-up is displayed to select the custom time range.
-
Select a day from Starting at drop-down list and select the Hour and Minute by using the slider.
-
Select the amount of time the data to be captured from For drop-down list.
The page displays the list of services that hit the server within the selected custom time range.
Error filter: You can filter the errors displayed from the total requests sent to the server within the selected time range. You can choose the options displayed from the Error Filter drop-down list.

- Include Errors: Selecting this option displays the count of errors displayed out of the requests sent to the server within the selected time range.
- Exclude Errors: Selecting this option excludes the count of errors from the list of metrics displayed.
- Errors Only: Selecting this option displays only those service requests that have errors.
Node Filter
Nodes represent the different server instances that comprise the environment. The name of the node is determined by the first value found from a JVM -D of VOLTMX_SERVER_NODE_NAME, the host name of the machine or the MAC address with a generated hash ID.
The performance of All the nodes is displayed by default. You can choose the nodes you want to monitor from the Node drop-down list.

Threshold
Threshold is a setting that determines the performance of services. You can set Warning or Critical thresholds for the given fields:
- Response Time (in ms.)
- Error Count
- Percentage of errors
When the value of any field exceed the threshold, the server sends a notification to your email address. Based on the values of the fields, you can identify the services that have a degraded performance.
The error percent, error count, and response time columns are color coded for quicker identification of services with degraded performance.
- Red indicates critical
- Amber indicates warning
- Green indicates no issues
The admin can set warning and critical thresholds globally for all services or can override the settings for individual services as expected response times can vary across services. Notifications are automatically sent to users through email when the response data exceeds the predefined threshold settings.
Note: You can set custom thresholds for individual services. These thresholds override the thresholds that are set globally.
To set a threshold globally, perform the following actions:
-
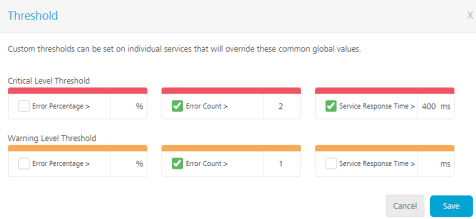
In Admin Console>> Monitoring>> click Threshold. The Threshold pop-up appears.
-
You can set the threshold using one or more as a combination of
- Percentage of Errors
- Count of Errors
- Service Response Time exceeding a certain value in milliseconds
Note: If a combination of thresholds is set, the email notification is sent even if one of the values is triggered.
For example, if the warning threshold is set for error > 5 and service response time > 5000, the warning notification is sent to the users if the error count>5 or if the service response time>5000.
The server calculates the parameters for every operation of the service.
Note: The parameters are calculated for the duration that you have selected for the monitoring data.
Note: Critical thresholds are expected to be higher than warning.
Global thresholds can be overridden with different threshold values at individual operations as some services are expected to take more time to respond.
For example, a three second response time is considered slow for a service, whereas a complicated orchestration service which connects to multiple back ends and receives more data as response can be expected to be normal even for eight seconds response time.
-
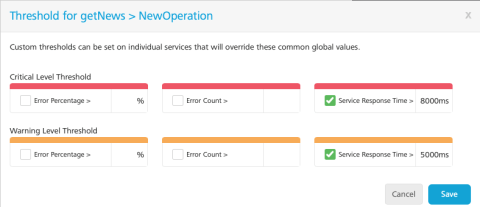
To set threshold for an individual service: In Admin Console>> Monitoring>>click Threshold icon next to service to set the threshold. The Threshold pop-up for the selected service appears.
-
Click the check box next to each parameter and enter a value to set a threshold. Critical level threshold must be greater than warning level threshold.
-
Once the threshold is set, click Save.
If the threshold exceeds the predefined settings, the data highlights with amber for warning and red for critical, irrespective of enabling the notifications.
For example, in the above screen shot, we have set a specific threshold for NewOperation in the getNews service. This allows the admin to ensure that unnecessary alerts are not triggered for this operation when its expected response time is higher than other services.
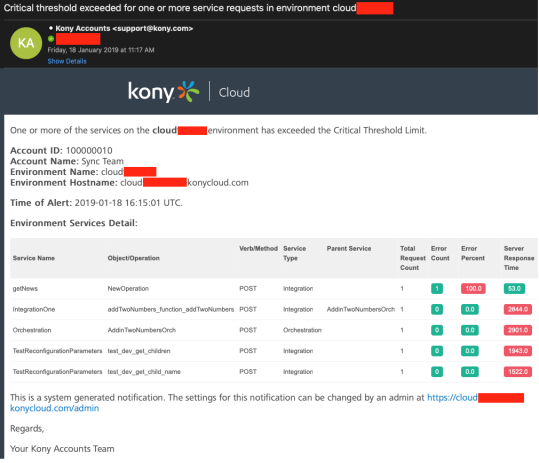
Notifications
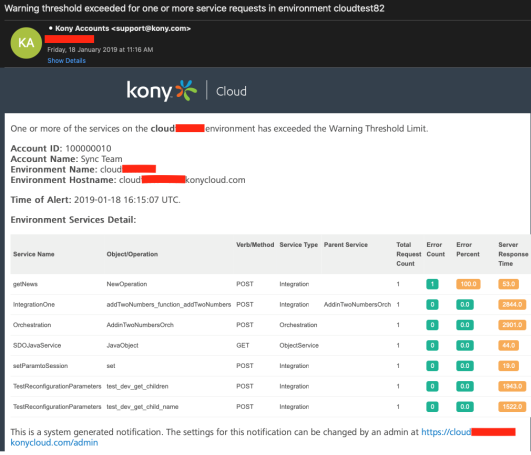
You can configure the time interval for monitoring the performance (ranging from 5 minutes to 60 minutes) and enable email notifications to be set for critical or warning thresholds independently. Email notifications can be sent to all account owners, or admins, or custom users who have access to the environment. The threshold criteria is evaluated by calculating the average performance data over a configurable time window.
The flexibility of configuring the time interval and setting the notifications independently allows the admin, for example, to check for warnings only once an hour and possibly notify the on-call support person, and for critical alerts send mails to all admins to ensure more people troubleshoot the issue.
To enable notifications at different levels, perform the following actions.
-
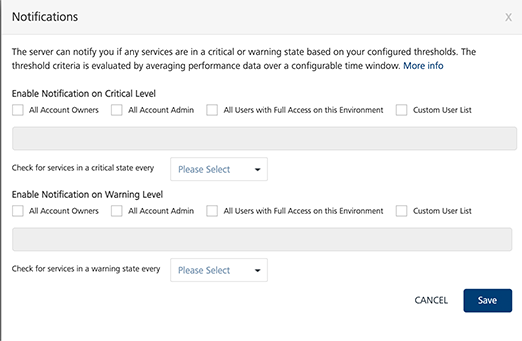
In Admin Console>> Monitoring>> click Notifications. The Notifications window appears.
-
Under Enable Notification on Critical level and/or Enable Notification on Warning Level, select any of the following options
- All Account Owners - Select the check box to enable notifications at critical level for all account owners.
- All Account Admin - Select the check box to send notifications to all admins of the account.
- All Users with Full Access on this Environment - Select the check box to send notifications to all the users having full access on this environment.
-
Custom User List - Select the check box to send notification to custom users. You can enter the email IDs of the custom users in the text box .
Note: Custom users must have access to the environment to receive the email alerts.
-
You can select the time interval to check the services in the critical (or) warning state. The available options are 5 mins, 10 mins, 15 mins, 20 mins, 30 mins, and 60 mins.
- Click Save to save the changes.
Email notifications are sent on Critical and Warning level thresholds.
Click here to view sample email alert for Critical and Warning threshold.
Sample email alert for Critical Threshold
Sample email alert for Warning threshold
Configuring Email Alerts (On-Premises)
To configure email alerts, perform the following actions:
-
Add the following server configuration parameters:
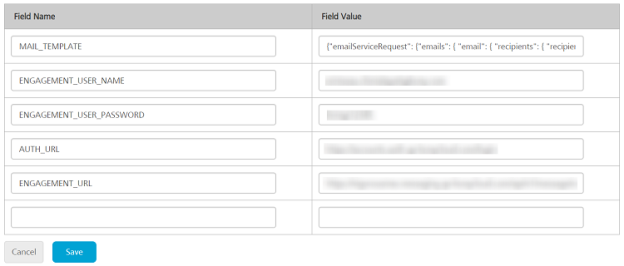
- MAIL_TEMPLATE: The Engagement email request payload API.
Sample Payload:
{
"emailServiceRequest": {
"emails": {
"email": {
"recipients": {
"recipient": [
{
"emailId": "$mailId",
"type": "TO"
}
]
},
"senderName": "VoltMX",
"subject": "$mailSubject",
"content": "<p> This is a system generated notification that one or more of the services has exceeded the threshold limit and your email is part of the notification distribution list for this alert. The settings for this notification can be changed by an admin at by logging to admin console</p> <p>Environment Services Detail: </p> $mailContent",
"priority": "true",
"startTimeStamp": 0,
"endTimeStamp": 0
}
}
```* **ENGAGEMENT\_USER\_NAME/ENGAGEMENT\_PASSWORD**: The Engagement user login credentials.
* **AUTH\_URL**: Auth service login URL to generate claims token.
* **ENGAGEMENT\_URL**: Engagement services runtime URL with API for adhoc email.
Example: `https://<runtime_url>/api/v1/message/email`.
Click **Save**.
2. Create custom servlet to make adhoc email request call to the Engagement services
package com.voltmx.sample;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.io.IOUtils;
import org.apache.commons.lang.StringEscapeUtils;
import org.apache.commons.lang.StringUtils;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import org.json.simple.JSONObject;
import org.json.simple.parser.JSONParser;
import com.hcl.voltmx.middleware.api.ServicesManagerHelper;
import com.hcl.voltmx.middleware.servlet.IntegrationCustomServlet;
@IntegrationCustomServlet(urlPatterns = {
"sendmail"
})
public class MailServlet extends HttpServlet {
private static final Logger LOGGER = LogManager.getLogger(MailServlet.class);
private static final long serialVersionUID = -7623066890220333243 L;
private String authToken;
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String json = IOUtils.toString(request.getInputStream(), "UTF-8");
try {
String requestpayload = ServicesManagerHelper.getServicesManager(request).getConfigurableParametersHelper()
.getServerProperty("MAIL_TEMPLATE");
Object obj = new JSONParser().parse(json);
JSONObject jsonObj = (JSONObject) obj;
JSONObject notifyList = (JSONObject) jsonObj.get("NotifyList");
String mailId = (String) notifyList.get("users");
JSONObject alerts_services_details = (JSONObject) jsonObj.get("alerts_services_details");
String mailContent = (String) alerts_services_details.get("services\.html_content");
String mailSubject = (String) jsonObj.get("type");
mailSubject = mailSubject.replace("_", " ");
requestpayload = requestpayload.replace("$mailId", mailId);
requestpayload = requestpayload.replace("$mailSubject", mailSubject);
requestpayload = requestpayload.replace("$mailContent", StringEscapeUtils.escapeJava(mailContent));
CloseableHttpResponse httpResponse = getAuthTokenAndCallAPI(request, requestpayload);
if (httpResponse.getStatusLine().getStatusCode() == 200) {
response.setContentType("application/json");
response.getWriter().write("{\"message\":\"Mail request initiated successfully\"}");
} else {
LOGGER.error("Faild to trigger mail, with response code {} ",
httpResponse.getStatusLine().getStatusCode());
response.setContentType("application/json");
response.getWriter().write("{\"message\":\"Failed to trigger mail\"}");
}
} catch (Exception e) {
LOGGER.error("Failed to trigger mail", e);
response.setContentType("application/json");
response.getWriter().write("{\"message\":\"Failed to trigger mail\"}");
}
}
private CloseableHttpResponse getAuthTokenAndCallAPI(HttpServletRequest request, String requestPayload)
throws Exception {
if (StringUtils.isBlank(authToken)) {
LOGGER.debug("Generating auth token using the configured user credentials");
authToken = getAuthToken(request);
}
String url = ServicesManagerHelper.getServicesManager(request).getConfigurableParametersHelper()
.getServerProperty("ENGAGEMENT_URL");
CloseableHttpResponse response = executeRequestAndGetResponse(url, requestPayload, authToken);
if (response.getStatusLine().getStatusCode() == 401 || response.getStatusLine().getStatusCode() == 403) {
authToken = getAuthToken(request);
response = executeRequestAndGetResponse(url, requestPayload, authToken);
}
return response;
}
private String getAuthToken(HttpServletRequest request) throws Exception {
String userId = ServicesManagerHelper.getServicesManager(request).getConfigurableParametersHelper()
.getServerProperty("ENGAGEMENT_USER_NAME");
String password = ServicesManagerHelper.getServicesManager(request).getConfigurableParametersHelper()
.getServerProperty("ENGAGEMENT_USER_PASSWORD");
String url = ServicesManagerHelper.getServicesManager(request).getConfigurableParametersHelper()
.getServerProperty("AUTH_URL");
CloseableHttpResponse response = executeRequestAndGetResponse(url,
"{\"userid\": \"" + userId + "\",\"password\": \"" + password + "\"}", null);
String responseContent = IOUtils.toString(response.getEntity().getContent(), "UTF-8");
Object claimTokenObj = ((JSONObject) new JSONParser().parse(responseContent)).get("claims_token");
if (claimTokenObj != null) {
return (String)((JSONObject) claimTokenObj).get("value");
} else {
LOGGER.debug("Failed to get the cliams token, check if the user credentials are valid");
}
return null;
}
private CloseableHttpResponse executeRequestAndGetResponse(String url, String payload, String authToken)
throws ClientProtocolException, IOException {
CloseableHttpClient client = HttpClients.createDefault();
HttpPost httpPost = new HttpPost(url);
httpPost.setEntity(new StringEntity(payload));
if (StringUtils.isNotBlank(authToken)) {
httpPost.setHeader("X-VoltMX-Authorization", authToken);
}
httpPost.setHeader("Accept", "application/json");
httpPost.setHeader("Content-type", "application/json");
CloseableHttpResponse httResponse = client.execute(httpPost);
return httResponse;
}
}
```
Note: Following are the third party libraries required to compile the MailServlet code:
- Commons-io-2.6.jar
- Commons-lang3-3.8.1.jar
- Httpclient-4.5.6.jar
- Log4j-api.jar
- Json-simple.jar
- Create a custom jar with the custom servlet created in the earlier step.
- Upload the asset to the Volt MX Foundry server and publish the app.
-
Configure the servlet endpoint URL -D parameter VOLTMX_SERVER_ALERTS_NOTIFY_ENDPOINT.
Example:
-DVOLTMX_SERVER_ALERTS_NOTIFY_ENDPOINT=http://<host>:<port>/services/sendmail.
Best Practices
-
The thresholds must be set appropriately to avoid false alarms.
-
Use caution while setting the alert monitoring interval.
For example, if alert interval is set at 5 minutes and the threshold criteria is met for every 5 minutes, an alert is sent for every such interval. To avoid such clutter, consider the time intervals for warning and critical and set individual thresholds.
-
Ensure that appropriate users are copied for email alerts.