Configuration and Setup for Foundry on Amazon EKS
Configure the properties file
-
Extract the
FoundryKube.zipfile. The zip file is organized as follows:
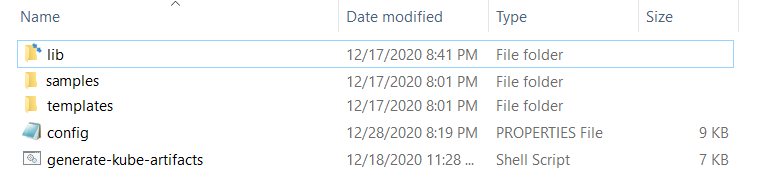
- lib: Contains dependent jars and helper bash functions
- samples: Contains sample Foundry deployments
- templates: Contains the following files
- foundry-app-tmpl.yml: YAML template for Foundry deployments
- foundry-db-tmpl.yml: YAML template for Foundry Database schema creation
- foundry-services.yml: YAML template for Foundry services
- foundry-ingress.yml: YAML template for Ingress configuration
- config.properties: Contains inputs that you must configure for the installation
- generate-kube-artifacts.sh: A user script that is used to generate required artifacts
As a result of executing the
generate-kube-artifacts.shscript, theartifactsfolder is created containing YAML configuration files. The YAML configuration files are generated based on theconfig.propertiesfile, and they must be applied later to deploy Volt MX Foundry on EKS. -
Update the
config.propertiesfile with relevant information.
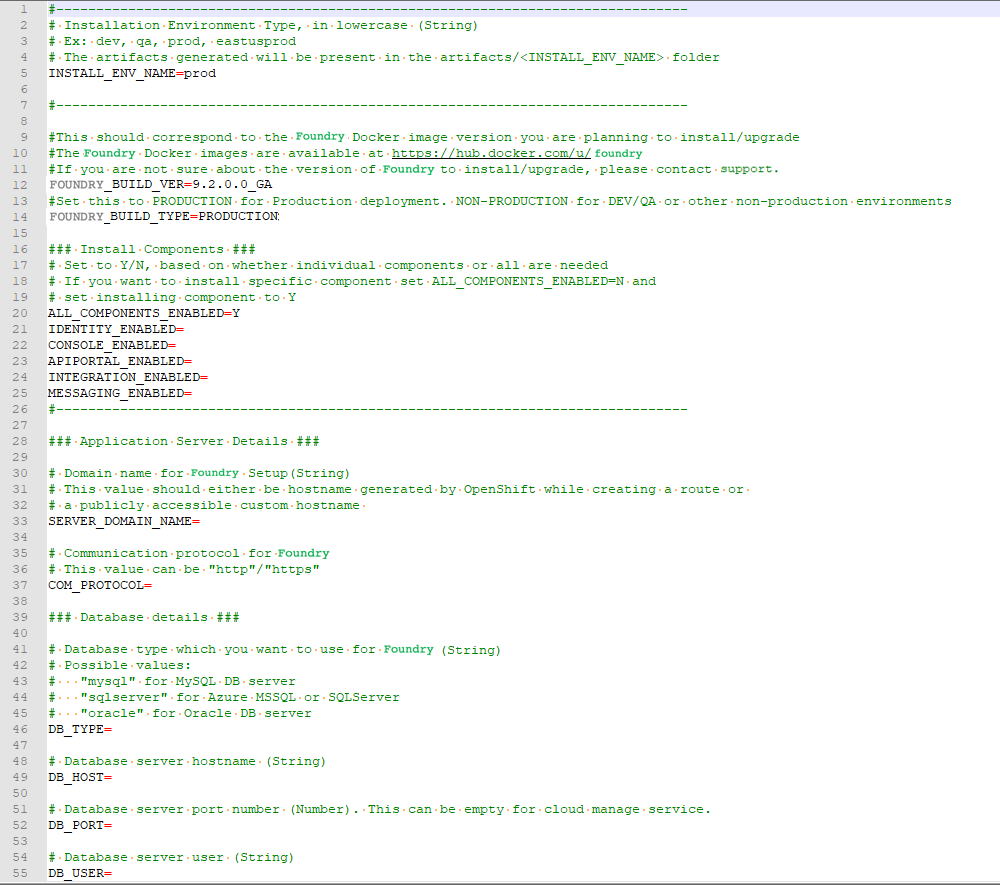
For more information about the properties, refer to the following section.
config.properties
-
INSTALL_ENV_NAME: The install environment name must be a in string value in lowercase. For example:
dev,qa,prod, oreastusprod.- IMAGE_REGISTRY_USERNAME - This is the email ID you use to log in.
- IMAGE_REGISTRY_PASSWORD - This is the CLI secret found under your User Profile in HCL Harbor.
-
VOLTMX_FOUNDRY_BUILD_VER: The build version of Foundry that you want to install. While upgrading, this specifies the build version to which you want to upgrade.
-
VOLTMX_FOUNDRY_BUILD_TYPE: The type of Foundry environment that must be created. For production environments, the value must be
PRODUCTION. For dev, QA, or other non-production environments, the value must beNON-PRODUCTION. -
Install Components: The following properties must be set to either Y (yes) or N (no). Make sure that at least one of the following input properties must be set to Y. If ALL_COMPONENTS_ENABLED is set to Y, the rest of the inputs can be left empty.
- ALL_COMPONENTS_ENABLED
- INTEGRATION_ENABLED
- IDENTITY_ENABLED
- MESSAGING_ENABLED
- CONSOLE_ENABLED
- APIPORTAL_ENABLED
- Application Server Details
- SERVER_DOMAIN_NAME: The Domain Name for Volt MX Foundry. This value should be the hostname of the LoadBalancer. For example: abc.companyname (DNS name).
- COM_PROTOCOL: The communication protocol for Volt MX Foundry. This value can be either http or https.
- Database Details
- DB_TYPE - The Database type that is used to host Volt MX Foundry. The possible values are:
- For MySQL DB server:
mysql - For Azure MSSQL or SQL Server:
sqlserver - For Oracle DB server:
oracle
- For MySQL DB server:
- DB_HOST - The Database Server hostname that is used to connect to the Database Server.
- DB_PORT– The Port Number that is used to connect to the Database Server. This can be empty for cloud manage service.
- DB_USER - The Database Username that is used to connect to the Database Server.
- DB_PASS - The Database Password that is used to connect to the Database Server. Make sure that the value is enclosed in single quotes, for example,
'password'. - DB_PASS_SECRET_KEY - This is the decryption key for the database password, which is required only if you are using an encrypted password.
- DB_PREFIX – This is the Database server prefix for Volt MX Foundry Schemas/Databases.
- DB_SUFFIX – This is the Database server suffix for Volt MX Foundry Schemas/Databases.
Note: * Database Prefix and Suffix are optional inputs. * In case of upgrade, ensure that the values of the Database Prefix and Suffix that you provide are the same as you had provided during the initial installation.
- If DB_TYPE is set as oracle, the following String values must be provided:
- DB_DATA_TS: Database Data tablespace name.
- DB_INDEX_TS: Database Index tablespace name.
- DB_LOB_TS: Database LOB tablespace name.
- DB_SERVICE: Database service name.
-
USE_EXISTING_DB: If you want to use an existing database from a previous Volt MX Foundry instance, set this property to Y. Otherwise, set the property to N.
If you want to use an existing database, you must provide the location of the previously installed artifacts (the location must contain the
upgrade.propertiesfile).For example: PREVIOUS_INSTALL_LOCATION =
/C/voltmx-foundry-containers-onprem/kubernetes.
-
Time Zone: The time zone must be set to maintain consistency between the application server and the database. This section contains the following property:
- TIME_ZONE: The country code of the time zone from the tz database. For more information, refer to List of tz database time zones. The default value is UTC.
- Readiness and Liveness Probes Details: The readiness and liveness probes are used to check the status of a container. The probes can check whether a container is ready to receive traffic, or if a container can be stopped and restarted. The following properties specify the initial delay (in seconds) of the probes for the Foundry components:
- IDENTITY_READINESS_INIT_DELAY
- IDENTITY_LIVENESS_INIT_DELAY
- CONSOLE_READINESS_INIT_DELAY
- CONSOLE_LIVENESS_INIT_DELAY
- INTEGRATION_READINESS_INIT_DELAY
- INTEGRATION_LIVENESS_INIT_DELAY
- ENGAGEMENT_READINESS_INIT_DELAY
- ENGAGEMENT_LIVENESS_INIT_DELAY
- Minimum and Maximum RAM percentage Details: These properties specify the minimum and maximum RAM (in percentage) that a Foundry component can use on the server. For example:
CONSOLE_MAX_RAM_PERCENTAGE="80". This section contains the following properties:- CONSOLE_MIN_RAM_PERCENTAGE
- CONSOLE_MAX_RAM_PERCENTAGE
- ENGAGEMENT_MIN_RAM_PERCENTAGE
- ENGAGEMENT_MAX_RAM_PERCENTAGE
- IDENTITY_MIN_RAM_PERCENTAGE
- IDENTITY_MAX_RAM_PERCENTAGE
- INTEGRATION_MIN_RAM_PERCENTAGE
- INTEGRATION_MAX_RAM_PERCENTAGE
- APIPORTAL_MIN_RAM_PERCENTAGE
- APIPORTAL_MAX_RAM_PERCENTAGE
- Container resource limits for memory and CPU: The resource limits are used to restrict resource usage for the Foundry components. The values must be provided in gigabytes (G) or megabytes (m). For example:
CONSOLE_RESOURCE_REQUESTS_CPU="300m". This section contains the following properties:- IDENTITY_RESOURCE_MEMORY_LIMIT
- IDENTITY_RESOURCE_REQUESTS_MEMORY
- IDENTITY_RESOURCE_REQUESTS_CPU
- CONSOLE_RESOURCE_MEMORY_LIMIT
- CONSOLE_RESOURCE_REQUESTS_MEMORY
- CONSOLE_RESOURCE_REQUESTS_CPU
- APIPORTAL_RESOURCE_MEMORY_LIMIT
- APIPORTAL_RESOURCE_REQUESTS_MEMORY
- APIPORTAL_RESOURCE_REQUESTS_CPU
- INTEGRATION_RESOURCE_MEMORY_LIMIT
- INTEGRATION_RESOURCE_REQUESTS_MEMORY
- INTEGRATION_RESOURCE_REQUESTS_CPU
- ENGAGEMENT_RESOURCE_MEMORY_LIMIT
- ENGAGEMENT_RESOURCE_REQUESTS_MEMORY
- ENGAGEMENT_RESOURCE_REQUESTS_CPU
- Custom JAVA_OPTS Details: The custom JAVA_OPTS properties specify Java options that must be configured for the Foundry components on the application server. The following properties can be used to configure additional Java options for the Foundry components:
- CONSOLE_CUSTOM_JAVA_OPTS
- ENGAGEMENT_CUSTOM_JAVA_OPTS
- IDENTITY_CUSTOM_JAVA_OPTS
- INTEGRATION_CUSTOM_JAVA_OPTS
- APIPORTAL_CUSTOM_JAVA_OPTS
- Number of instances to be deployed for each component: These properties specify the number of instances that must be deployed for every component. This section contains the following properties:
- IDENTITY_REPLICAS
- CONSOLE_REPLICAS
- APIPORTAL_REPLICAS
- INTEGRATION_REPLICAS
- ENGAGEMENT_REPLICAS
Deploy Foundry on Amazon EKS
After you update the config.properties file, follow these steps to deploy Volt MX Foundry on Amazon EKS:
-
Generate the foundry services by running the following command:
./generate-kube-artifacts.sh config.properties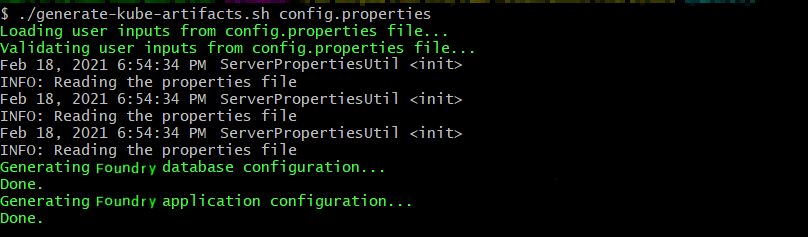
-
Create the services by running the following command:
kubectl apply -f ./artifacts/<INSTALL_ENV_NAME>/foundry-services.yml<INSTALL_ENV_NAME>is the install environment name input that you provided in theconfig.propertiesfile. -
Create the ingress controller and the internet facing application load balancer (ALB). For more information, refer to the following blog post: Kubernetes Ingress with AWS ALB Ingress Controller
Use the
foundry-ingress.ymlfile, which will map the created services to the load balancer paths.The specified process generates a load balancer domain name. Volt MX recommends that you use a custom domain name and terminate your SSL connection at the public load balancer. You need to obtain a custom domain name from a DNS provider and an SSL certificate. To generate a certificate for your custom domain name and the corresponding ARN (Amazon Resource Name), refer to Requesting a public certificate.
The generated ARN needs to be updated in the annotations section of the
foundry-ingress.ymlfile as shown in the following screenshot:
Note:
- All foundry services are exposed by using a single ALB.
- You need to create a security group rule to allow traffic from the ALB to the EC2 Managed nodes on the 8080 port, which is the listen port for the Foundry Services.
- The Foundry components for accounts, mfconsole, and workspace share the same deployment and service. Therefore, while creating the ingress objects for accounts, mfconsole, and workspace, the paths are mapped to the same service: voltmx-foundry-console.
Make sure that the format of the route location is as follows:
<scheme>://<common_domain_name>/<foundry_context_path>For example, https://voltmx-foundry.domain/mfconsole
Reference table for the mapping of paths and service names:
| Foundry Component | Foundry Service Name | Context Path |
|---|---|---|
| mfconsole | voltmx-foundry-console | /mfconsole |
| workspace | voltmx-foundry-console | /workspace |
| accounts | voltmx-foundry-console | /accounts |
| Identity | voltmx-foundry-identity | /authService |
| Integration | voltmx-foundry-integration | /admin |
| Services | voltmx-foundry-integration | /services |
| apps | voltmx-foundry-integration | /apps |
| Engagement | voltmx-foundry-engagement | /kpns |
| ApiPortal | voltmx-foundry-apiportal | /apiportal |
Deploy Kubernetes artifacts
After deploying the Foundry components on EKS, follow these steps to deploy the remaining Foundry Kubernetes artifacts:
-
Create the database schema by executing the following command.
Thekubectl apply -f ./artifacts/<INSTALL_ENV_NAME>/foundry-db.yml<INSTALL_ENV_NAME>is the name of the install environment that you provided in theconfig.propertiesfile. -
The previous step executes a job that is responsible for creating the schemas. Verify the completion of the job by executing the following command.
kubectl get job
-
Create the Foundry deployments by executing the following command.
kubectl apply -f ./artifacts/<INSTALL_ENV_NAME>/foundry-app.yml
Based on thedefault replica countthat is provided in theconfig.propertiesfile, one deployment of every Foundry component is created. The Foundry deployments can be scaled up later as required.
Launch the Foundry Console
-
After all the Foundry services are up and running, launch the Foundry console by using the following URL.
<scheme>://<foundry-hostname>/<mfconsole>
The <scheme> is <http> or <https> based on your domain. The <foundry-hostname> is the host name of your publicly accessible Foundry domain.
2. After you launch the Foundry Console, create an administrator account by providing the appropriate details.
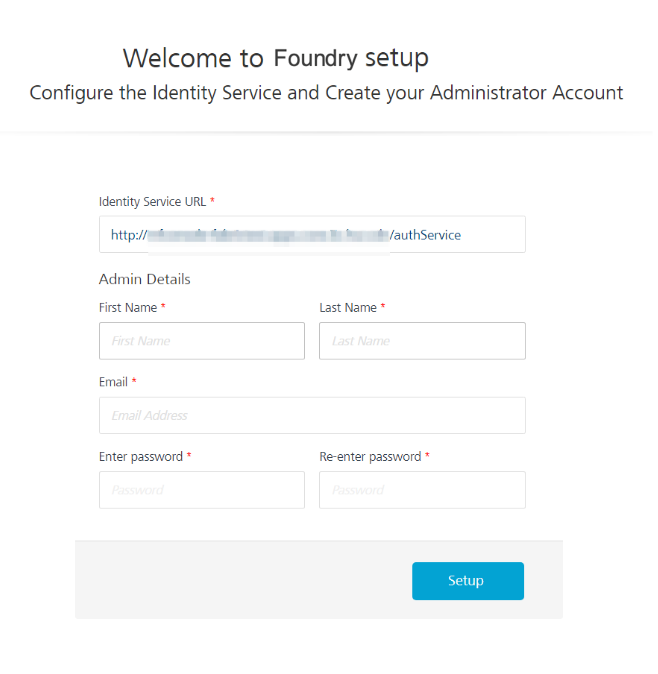
After you create an administrator account, you can sign-in to the Foundry Console by using the credentials that you provided.
Data Plane Configuration Options
AWS Fargate is a computation engine for containers. With AWS Fargate, you do not require servers, and you can manage and pay for resources based on the number of applications. As all the apps are isolated in Fargate, you also get improved security.
With Amazon EKS, you can create a data plane that consists of a Fargate profile, or a combination of both EC2 instances and a Fargate profile as shown in the following diagram:
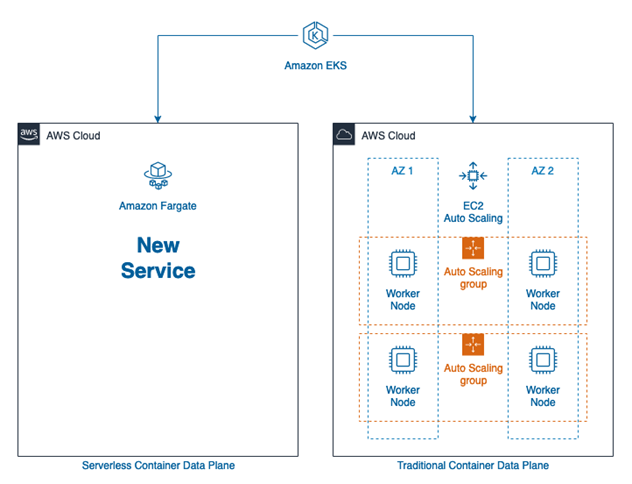
For the advantages and disadvantages of the various data plane options, refer to the following table:
| Data Plane Architecture | Advantages | Disadvantages |
|---|---|---|
| Managed EC2 |
|
|
| AWS Fargate |
|
|
| Mixed Mode |
|
|
The choice of Managed EC2, Fargate, or Mixed Mode depends on what works best based on the advantages and disadvantages that are highlighted in the table. For more information, refer to the Amazon documentation, especially the section on Fargate Pricing.
Steps to setup a Fargate data plane
- Create a Fargate Profile. Select the namespace as default while creating the profile.
Note: All the generated foundry artifacts are configured with the default namespace. Unless you want to deploy the artifacts to a different namespace, no further configuration is needed.
- Deploy the Ingress controller to the Fargate profile. profile by following the steps in the following blog post: How do I set up the AWS Load Balancer Controller on an Amazon EKS cluster for Fargate?
- Deploy the Foundry artifacts as described in the earlier sections. For more information, refer to Deploying Foundry on Amazon EKS.
Steps to setup a Mixed data plane
- Extra planning is required to decide which components must be deployed to the EC2 managed data plane and which components must be deployed to the Fargate profile.
- Based on the planning, while creating a Fargate profile, you need to specify the namespace on which the foundry components need to be deployed.
- The generated Foundry artifact YAML files need to be edited to specify the namespace on which the deployment must occur.
- An Ingress object from one namespace cannot communicate with services in another namespace. To work around this issue, you need to create ingress objects that correspond to the services that are deployed in the namespace. The
alb.ingress.kubernetes.io/group.nameannotation can be used to group both ingress objects together and ensure that a single ALB is provisioned by Amazon. - The
foundry-common-secretsneed to be duplicated in both namespaces so that it can be accessed by the deployments in both namespaces.
Note: You can refer to the
Samples/mixedDataPlanefolder in theFoundryKube.zipfile for a sample configuration where the Identity and Integration components are deployed to the foundry-runtime namespace in a Fargate data plane; and the rest of the components (Console, API Portal, and Engagement) are deployed in the EC2 managed data plane.